La (sentrerte) data lagres i en $ n \ ganger d $ matrise $ \ mathbf X $ med $ d $ funksjoner (variabler) i kolonner og $ n $ datapunkter i rader. La kovariansmatrisen $ \ mathbf C = \ mathbf X ^ \ top \ mathbf X / n $ ha egenvektorer i kolonner på $ \ mathbf E $ og egenverdier på diagonalen til $ \ mathbf D $, slik at $ \ mathbf C = \ mathbf E \ mathbf D \ mathbf E ^ \ top $.
Så det du kaller "normal" PCA-blekingstransformasjon er gitt av $ \ mathbf W_ \ mathrm {PCA} = \ mathbf D ^ {- 1/2} \ mathbf E ^ \ top $, se f.eks mitt svar i Hvordan bleke dataene ved hjelp av hovedkomponentanalyse?
Denne blekingstransformasjonen er imidlertid ikke unik. Faktisk vil hvite data forbli hvite etter enhver rotasjon, noe som betyr at enhver $ \ mathbf W = \ mathbf R \ mathbf W_ \ mathrm {PCA} $ med ortogonal matrise $ \ mathbf R $ også vil være en blekingstransformasjon. I det som kalles ZCA-bleking tar vi $ \ mathbf E $ (stablet sammen egenvektorer av kovariansmatrisen) som denne ortogonale matrisen, dvs. $$ \ mathbf W_ \ mathrm {ZCA} = \ mathbf E \ mathbf D ^ {- 1 / 2} \ mathbf E ^ \ top = \ mathbf C ^ {- 1/2}. $$
En definerende egenskap for ZCA-transformasjon ( noen ganger også kalt "Mahalanobis transformation ") er at det resulterer i hvite data som er så nær som mulig de opprinnelige dataene (i minste firkant). Med andre ord, hvis du vil minimere $ \ | \ mathbf X - \ mathbf X \ mathbf A ^ \ top \ | ^ 2 $ med forbehold om at $ \ mathbf X \ mathbf A ^ \ top $ blir bleket, så bør du ta $ \ mathbf A = \ mathbf W_ \ mathrm {ZCA} $. Her er en 2D-illustrasjon:
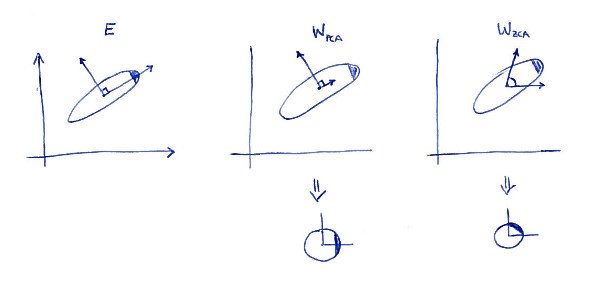
Venstre delplott viser dataene og hovedaksene. Legg merke til den mørke skyggen i det øvre høyre hjørnet av fordelingen: den markerer retningen. Rader med $ \ mathbf W_ \ mathrm {PCA} $ vises på den andre delplottet: dette er vektorene dataene projiseres på. Etter bleking (nedenfor) ser fordelingen seg rundt, men legg merke til at den også ser rotert ut --- mørkt hjørne er nå på østsiden, ikke på nordøstsiden. Rader med $ \ mathbf W_ \ mathrm {ZCA} $ vises på den tredje delplottet (merk at de ikke er ortogonale!). Etter bleking (under) ser distribusjonen rundt og den er orientert på samme måte som opprinnelig. Selvfølgelig kan man komme fra PCA-hvite data til ZCA-hvite data ved å rotere med $ \ mathbf E $.
Begrepet "ZCA" ser ut til å ha blitt introdusert i Bell og Sejnowski 1996 i sammenheng med uavhengig komponentanalyse, og står for "zero-phase component analysis". Se der for mer informasjon. Mest sannsynlig kom du over dette begrepet i sammenheng med bildebehandling. Det viser seg at når de brukes på en haug med naturlige bilder (piksler som funksjoner, hvert bilde som datapunkt), ser hovedaksene ut som Fourier-komponenter med økende frekvenser, se første kolonne i figur 1 nedenfor. Så de er veldig "globale". På den annen side ser rader med ZCA-transformasjon veldig "lokale" ut, se den andre kolonnen. Dette er nettopp fordi ZCA prøver å transformere dataene så lite som mulig, og slik at hver rad bedre bør være nær en av de opprinnelige basisfunksjonene (som ville være bilder med bare en aktiv piksel). Og dette er mulig å oppnå, fordi korrelasjoner i naturlige bilder for det meste er veldig lokale (så de-korrelasjonsfiltre kan også være lokale).

Oppdater
Flere eksempler på ZCA-filtre og bilder transformert med ZCA er gitt i Krizhevsky, 2009, Learning Multiple Layers of Features from Tiny Images, se også eksempler i @ bayerj's svar (+1).
Jeg tror disse eksemplene gir en ide om når ZCA-bleking kan være å foretrekke fremfor PCA-en. ZCA-hvite bilder ligner nemlig fremdeles på normale bilder mens PCA-hvite bilder ikke ser ut som normale bilder. Dette er sannsynligvis viktig for algoritmer som nevrale nettverk av konvolusjon (som f.eks. Brukt i Krizhevskys papir), som behandler nabopiksler sammen og i så stor grad er avhengige av de lokale egenskapene til naturlige bilder. For de fleste andre maskinlæringsalgoritmer bør det være absolutt irrelevant om dataene blir bleket med PCA eller ZCA.