Absolutt kan gjennomsnittet pluss en sd overstige den største observasjonen.
Tenk på prøven 1, 5, 5, 5 -
den har gjennomsnitt 4 og standardavvik 2, så gjennomsnittet + sd er 6, en mer enn prøven maksimalt. Her er beregningen i R:
> x = c (1,5,5,5) > mean (x) + sd (x) [1] 6
Det er en vanlig forekomst. Det har en tendens til å skje når det er en rekke høye verdier og en hale til venstre (dvs. når det er sterk venstre skjevhet og en topp nær maksimum).
-
The samme mulighet gjelder for sannsynlighetsfordelinger, ikke bare prøver - populasjonsgjennomsnittet pluss populasjonen sd kan lett overstige den maksimalt mulige verdien.
Her er et eksempel på en $ \ text {beta} (10, \ frac {1} {2}) $ tetthet, som har en maksimal mulig verdi på 1:
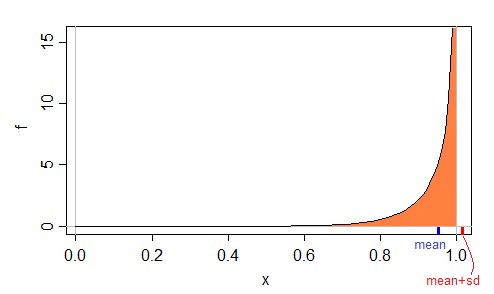
I dette tilfellet kan vi se på Wikipedia-siden for beta-distribusjon, som sier at gjennomsnittet er:
$ \ operatorname {E} [X] = \ frac {\ alpha} {\ alpha + \ beta} \! $
og avviket er:
$ \ operatorname {var} [X] = \ frac {\ alpha \ beta } {(\ alpha + \ beta) ^ 2 (\ alpha + \ beta + 1)} \! $
(Selv om vi ikke trenger å stole på Wikipedia, siden de er ganske enkle å utlede.)
Så for $ \ alpha = 10 $ og $ \ beta = \ frac {1} {2} $ har vi gjennomsnitt $ \ ca 0,9523 $ og sd $ \ ca 0,0628 $, så betyr + sd $ \ omtrent 1.0152 $, mer enn det mulige maksimum på 1.
Det vil si at det er lett mulig å ha en verdi på middel + sd som ikke kan observeres som en dataverdi .
--
For alle situasjoner der modusen var maksimalt, må Pearson-modus skjevhet bare være $ < \, - 1 $ for gjennomsnitt + sd for å overskride maksimumet. Det kan ta hvilken som helst verdi, positiv eller negativ, slik at vi kan se at det er lett mulig.
-
Et nært beslektet problem blir ofte sett med konfidensintervaller for et binomium andel, der et ofte brukt intervall, kan det normale tilnærmelsesintervallet produsere grenser utenfor $ [0,1] $.
Vurder for eksempel et normalt tilnærmelsesintervall på 95,4% for populasjonsandelen suksesser i Bernoulli-studier (utfallet er henholdsvis 1 eller 0 som representerer suksess og fiaskohendelser), hvor 3 av 4 observasjoner er "$ 1 $" og en observasjon er "$ 0 $".
Da er den øvre grensen for intervallet $ \ hat p + 2 \ ganger \ sqrt {\ frac {1} {4} \ hat p \ left (1 - \ hat p \ right)} = \ hat p + \ sqrt {\ hat p (1 - \ hat p)} = 0,75 + 0,433 = 1,183 $
Dette er bare eksemplets gjennomsnitt + det vanlige estimatet for sd for binomialet ... og produserer en umulig verdi.
Den vanlige prøven sd for 0,1,1,1 er 0,5 i stedet for 0,433 (de skiller seg ut fordi det binomiale ML-estimatet av standardavviket $ \ hat p (1- \ hat p) $ tilsvarer å dele variansen med $ n $ i stedet for $ n-1 $). Men det gjør ingen forskjell - i begge tilfeller overstiger middel + sd størst mulig andel.
Dette faktum - at et normalt tilnærmingsintervall for binomialet kan produsere "umulige verdier" blir ofte notert i bøker og papirer . Imidlertid har du ikke å gjøre med binomial data. Likevel er problemet - det betyr + et visst antall standardavvik ikke en mulig verdi - analogt.
-
I ditt tilfelle er den uvanlige "0" -verdien i prøven din gjør sd stort mer enn det trekker gjennomsnittet ned, og derfor er middel + sd høyt.

-
( Spørsmålet ville i stedet være - med hvilken begrunnelse ville det være umulig? - for uten å vite hvorfor noen tror det er et problem i det hele tatt, hva tar vi for oss?)
Logisk selvfølgelig viser man at det er mulig ved å gi et eksempel der det skjer. Du har allerede gjort det. I mangel av en oppgitt grunn til at det skulle være annerledes, hva skal du gjøre?
Hvis et eksempel ikke er tilstrekkelig, hvilket bevis vil da være akseptabelt?
Det er egentlig ikke noe poeng å bare peke på en uttalelse i en bok, siden enhver bok kan uttale seg feilaktig - jeg ser dem hele tiden. Man må stole på direkte demonstrasjon av at det er mulig, enten et bevis i algebra (man kan konstruere fra betaeksemplet ovenfor for eksempel *) eller ved numerisk eksempel (som du allerede har gitt), som alle kan undersøke sannheten om selv .
* whuber gir de nøyaktige forholdene for beta-saken i kommentarer.